

애플리케이션이 여러 서버에 분산된 자원을 호출할 경우 이 자원들의 물리적 위치를 알고있어야한다.
그래서 서비스 위치 확인은 대개 DNS, Load Balancer의 조합으로 해결되었다.
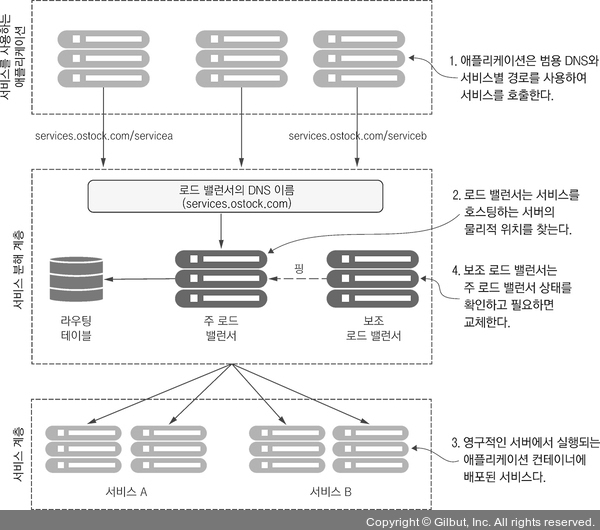
전통적 시나리오에서는 서비스 소비자에게 요청받은 로드 밸런서 라우팅 테이블 항목에는 서비스를 호스팅하는 한 개 이상의 서버 목록이 존재한다.
로드 밸런서는 이 목록에서 서버 하나를 골라 요청을 전달한다.
이러한 기존 방식의 서비스 인스턴스는 한 개 이상의 애플리케이션 서버에 배포되었다.
애플리케이션의 수는 대개 고정적이었고(ex 서비스를 호스팅하는 애플리케이션의 수가 늘거나 줄지 않음) 그리고 영속적이었다. 즉 애플리케이션을 실행 중인 서버가 고장나면 사용하던 것과 동일한 IP 주소와 구성으로 복구된다.
고가용성을 위해 유휴 상태의 보조 로드 밸런서는 핑 신호를 보내 로드 밸런서의 생사여부를 확인했다.
그리고 주 로드 밸런서가 죽어있다면 보조 로드 밸런서는 활성화되고, 주 로드 밸런서의 IP를 이어받아 요청을 처리했다.
이러한 모델은 사방이 벽으로 둘러싸인 회사 데이터 센터 안에서 실행되는 애플리케이션과 고정적인 서버에서 실행되는 비교적 적은 수의 서비스에서 잘 작동하지만 클라우드기반 마이크로서비스 애플리케이션에서는 잘 동작하지 않는다.
단일 장애 지점
로드 밸런서가 다운되면 이것에 의존하던 모든 애플리케이션도 함께 다운된다.
로드 밸런서를 고가용성 있게 만들더라도 애플리케이션 인프라스트럭처 안에서는 중앙 집중식 관문이 될 가능성이 높다.
수평 확장 능력 제한
상용 로드 밸런서는 이중화 모델과 라이선싱 비용이라는 두 가지 요소의 제약을 받는다.
대부분의 상용 로드 밸런서들은 이중화를 위해 핫스왑(운영 시스템에 영향을 안주고 부품 교체) 모델을 사용하므로 로드 처리할 서버 하나만 동작한다.
즉 보조 로드 밸런서는 주 로드 밸런서가 다운된 경우 페일오버만을 위해 존재한다.
본질적으로 하드웨어 제약을 받고 상용 로드 밸런서는 좀 더 가변적인 모델이 아닌 고정된 용량에 맞추어져 제한적인 라이선싱 모델을 갖고있다.
로드 밸런서 대부분은 고정적으로 관리된다.
이 로드 밸런서들은 대부분 동적으로 서비스를 신속히 등록하고 취소하도록 설계되어있지 않다.
중앙 집중식 데이터베이스를 사용해 경로 규칙을 저장하고 대개 공급업체의 독점적인 API를 사용해야 새로운 경로를 저장할 수 있다.
로드 밸런서는 프록시 역할을 한다.
로드 밸런서는 애플리케이션 서버의 프록시 역할을 한다. 이 변환 계층은 수동으로 서비스 매핑 규칙을 정의하고 배포해야하므로 서비스 인프라스터럭처의 복잡성을 가중시킨다.
또한 전통적 로드 밸런서 시나리오에는 새로운 서비스 인스턴스가 시작할 때 로드밸런서에 등록되지 않는다.
이러한 네 가지 이유로 서비스 디스커버리는 DNS, Load Balancer 방식으로 사용되지 않는다.
여기서 오해하지 말아야할게 DNS, Load Balancer가 나쁘다는 것이 절대 아니다.
일단 이 방식은 중앙 집중식 네트워크 인프라에서는 잘 작동한다.
그리고 로드 밸런서는 SSL 종료를 처리하고 서비스 포트 보안을 관리하는 데 여전히 중요한 역할을 한다.
로드 밸런서 뒷단에는 모든 서버에 대한 들어오고 나가는 포트의 접근을 제한할 수 있다.
이러한 최소 네트워크 접근 개념은 종종 PCI 규정 준수처럼 산업 표준 인증에 대한 요구사항을 충족하려고 할 때 중요한 요소가 된다.
'Server & Infra.' 카테고리의 다른 글
| [Kafka] 파티션 할당 전략 (2) | 2024.04.12 |
|---|---|
| [Kafka] 리밸런싱 (0) | 2024.04.12 |
| [MongoDB] MongoDB의 데이터 복구 (0) | 2024.03.21 |
| [K8s] Namespace, ResourceQuota, LimitRange (0) | 2024.03.21 |
| [MSA] Saga Pattern (0) | 2024.03.21 |